The loss function is a crucial component to training neural nets. It allows us to get a measure of how well our neural net is doing.
Let’s take a look at the mean squared error loss:

is the final output from our net
is our label (the value we were expecting to get)
Even if you are unfamiliar with the mean squared error loss, it should hopefully be plausible to you that this function could measure the difference between how our network is doing, and how we hope it would do.
Now I will introduce a different loss function; the cross-entropy loss:
![L = -\dfrac{1}{n}\sum_x[y \cdot ln(a) + (1 - y)ln(1 - a)]](https://s0.wp.com/latex.php?latex=L+%3D+-%5Cdfrac%7B1%7D%7Bn%7D%5Csum_x%5By+%5Ccdot+ln%28a%29+%2B+%281+-+y%29ln%281+-+a%29%5D+&bg=ffffff&fg=000&s=2&c=20201002)
Woah! What the…? Where did this come from?
The Problem with Sigmoid Neurons
Let’s take a step back and talk about a fundamental problem with training a neural network of sigmoid neurons.
Here is the graph of the sigmoid function:
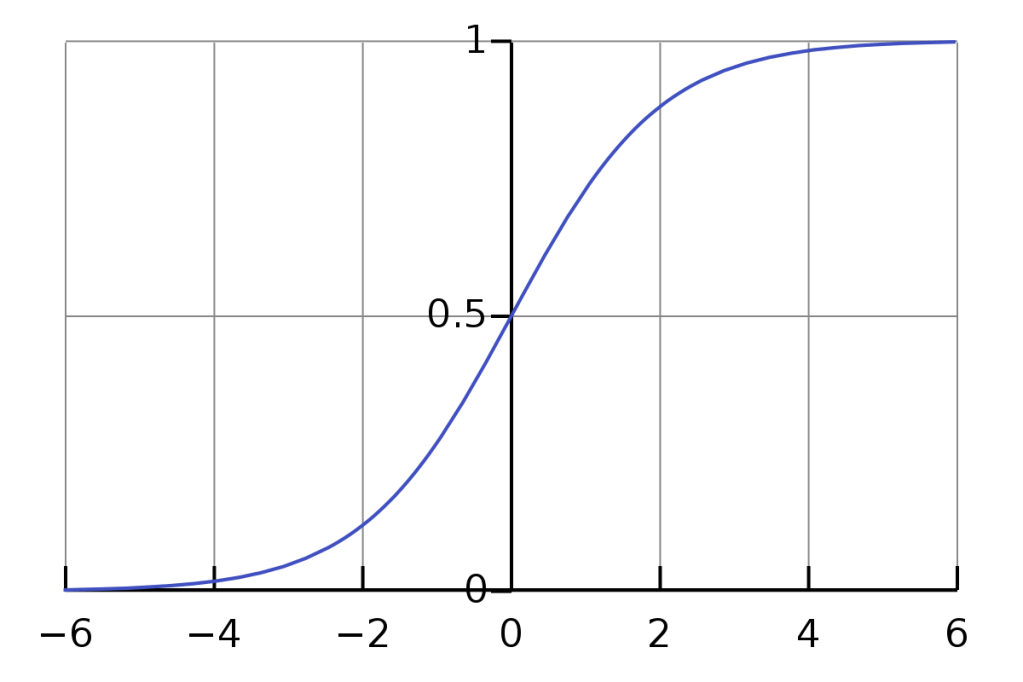
As you can see, the function gets very flat as the inputs to the sigmoid (our weighted sums) get high 

This will slow down the rate at which our neural net learns. It is particularly a problem when this 0 term appears in the calculation of the gradients in our output layer, because those gradients will propagate backward into the rest of our net. A tiny gradient in our output layer will slow down learning tremendously.
So what can we do? We want to get rid of the 
Getting rid of
The equation for the gradient of the bias is:

Where

We want the gradient for the bias to be equal to:

No 
We know that the derivative of the sigmoid function is equal to (see The Derivative of the Sigmoid Function):

In this case, because we are dealing with output neurons, 


Now, let’s plug the value we said we wanted for 

And solve for 

Great! This is the derivative of our ideal loss function. Now, how do we use this to find our ideal loss function? We integrate with respect to
Let’s do it step-by-step:

The first thing we want to do is break this fraction down using partial fraction decomposition:

To add the two fractions on the left side of this equation we need to get them under a common denominator:

Let’s ignore the denominator for now and solve this equation for 


We want to plug in values for 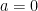


Now we want to make 


Now we plug those back into our decomposed fraction:

Taking the integral of this will be much easier:

Let’s do it term by term and then combine them together. We’ll start with the first term:

Rewriting it as:

Makes it obvious that the integral of this is:

Now the next term:

Once again we will rewrite it like we did the first term:

This one is a little trickier, but we will use u-substitution to integrate: Let


This gives us:

Plugging the substituted value back in:

Now we combine our integrated terms:

Does that look familiar?
It’s the cross-entropy loss function for one of our training data.
The find the total value of the cross entropy loss by average all of these values:
Conclusion
The cross-entropy loss has an advantage over mean squared error loss in certain situations because it avoids the saturation problem inherent to sigmoid neurons.
The cross-entropy loss is well suited to classification tasks in particular. When the model is confidently wrong, the gradients during backpropagation will be much larger and it will correct much faster.
I hope this post has given you some insight into where the cross-entropy loss function comes from, and the motivation behind it.

Leave a comment