Every matrix represents a linear transformation.
A special kind of matrix, called a diagonal matrix is very easy to interpret:

It should be obvious why we call this a diagonal matrix. It has non-zero entries along the main diagonal and zeros everywhere else.
It should also not take much to imagine what the linear transformation represented by this matrix would look like. A vector that was transformed by this matrix would have its 


Consider the example: 

Here’s another matrix:

It’s much harder to intuitively understand what linear transformation this matrix represents. This is still a simple 2×2 matrix, but notice how much more difficult it is to intuit what this matrix is doing simply because it is not diagonal.
As you increase the size of this matrix it would become impossible to interpret what linear transformation this matrix represents. That is not true of diagonal matrices. Diagonal matrices are always simple scaling/stretching, no matter how large they are.
Okay, diagonal matrices are great. So what? 
As long as the matrix is square we can perform a factorization called eigendecomposition.
Eigenvalues and Eigenvectors
A matrix’s eigenvectors are any vectors that satisfy this equation:

An eigenvector is a vector that, when multiplied by 
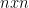

How do we find these eigenvalues and eigenvectors?
The equation above can be rewritten like this:

We basically just subtracted 
Factoring out the

This equation is telling us that the matrix 
Obviously, the zero vector itself multiplied by any matrix gives us the zero vector. We don’t care about that.
We want some other non-zero vector that, when multiplied by 

We know 




Great! Now we have our eigenvalues. We can use them to compute our eigenvectors:

To solve this system of linear equations we can get the matrix into reduced row echelon form, then solve the system:




The second eigenvector is computed in the same way. We get:

Eigendecomposition
Eigendecomposition is a way of factoring any square matrix into 3 different matrices multiplied together:

is a diagonal matrix of eigenvalues
is an orthogonal matrix of eigenvectors
We did most of the work needed for this factorization in the previous section about finding eigenvalues and eigenvectors.
The diagonal matrix

The fact that they are in descending order is very important. The magnitudes of the eigenvalues tell us how much of the linear transformation represented by
We already have our eigenvectors, which will make up the columns of 

It will not always be the case that the eigenvectors we found using the method in the previous section are orthogonal. This is a special property of symmetric matrices (which is why I chose this
So all together our final matrix factorization for

How do we interpret the Eigendecomposition
Now that we have our factorization it’s worth going over how we interpret it.
This is essentially a change of basis. 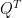
This factorization is powerful because it allows us to understand
There are many variations on this motif of “diagonalizing” matrices — factoring them such that one of the factors is a diagonal matrix that is easy to interpret.
Eigendecomposition is great, but it has one unfortunate requirement: it requires a square matrix. In reality we are not always lucky enough to have a square matrix.
In the next blog post I will talk about another, closely related matrix factorization: Singular Value Decomposition. SVD can be performed on any matrix and it’s applications are very powerful.

Leave a comment