Introduction
This is the second installment in a series of blog posts about Support Vector Machines. If you have not read the first blog post, I highly recommend you go back and read it before continuing to this blog post.
Last time we looked at how to define the ideal hyperplane to linearly separate two classes of data. We ended up deriving this equation for the margin:

The margin is the distance between the two closest points of each class. These two points are called the “support vectors”.
Optimizing the Margin
We want to maximize the margin to give ourselves as much breathing room as possible between the two classes. The margin is given by:
Because the magnitude of the weight vector is in the denominator, we can increase the margin by lowering that magnitude.
This means that, mathematically, our optimization problem is simply:

Subject to a few constraints:
All of the training data points in the positive class need to fall on or to the right of the positive support vector:

And all of the points for the negative class must fall on or to the left of the negative support vector:

Because all of the 

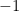


This problem is called the SVM primal. If you have encountered Support Vector Machines before, you may have also seen it in this form:

subject to:
These are the same optimization problem. This form simply makes some of the math easier (hint: we will be taking derivatives). We will use this form going forward, but just know that is the same problem as the one we derived above.
Optimization Basics
Mathematical optimization techniques can help us find the maximum value or minimum value of a function.
Suppose we wanted to find the minimum of this function:

In mathematical optimization, the function we want to optimize is called an objective function. You will sometimes hear it referred to as a loss function, especially in machine learning contexts.
I will write optimization problems with a 


Our goal is to find the values of 
First, we differentiate:


Solving for


We know for certain that these values for
So can we use this technique to optimize the margin in the SVM primal? Unfortunately this by itself is not enough, because of the constraints. We will need more mathematical tools in our toolbox to solve this problem.
Lagrange Multipliers
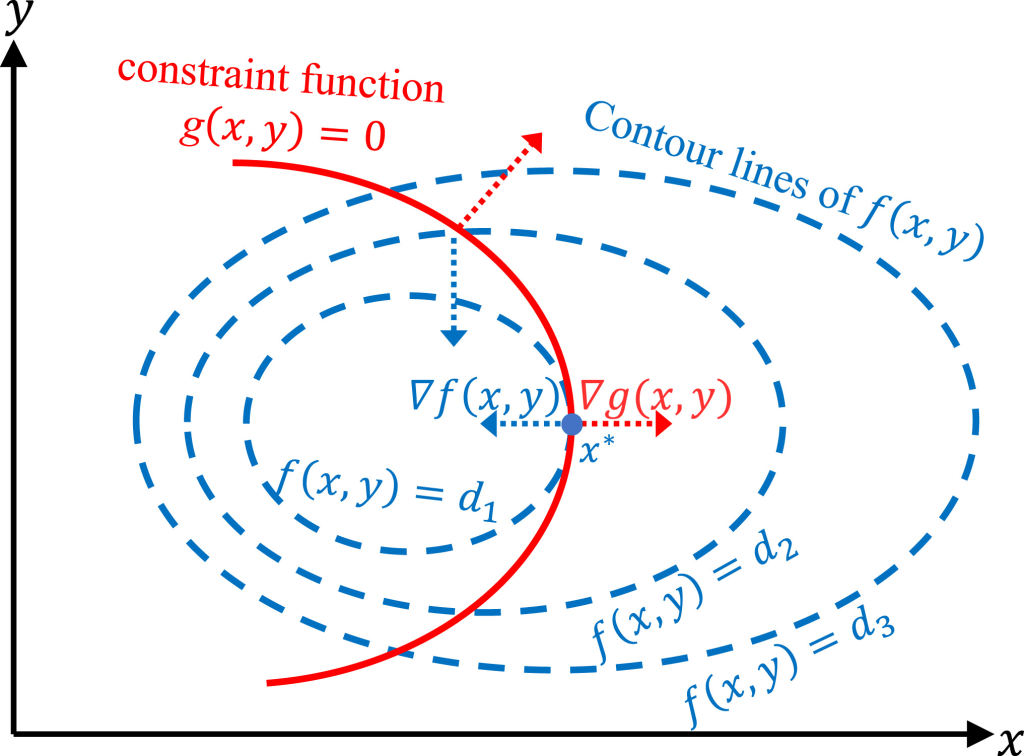
Imagine we have a function:

A two variable function is a surface. All along that surface are level curves (contour lines).
Now imagine we have a constraint:

Where 



The level curve for 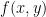
The contour lines are either falling or rising. Where they intersect
At that point, the level curves will either have the same tangent or parallel tangents. This means that they will have normal vectors that are scalar multiples of each other (or exactly the same).
The vectors normal to these level curves are the gradient vectors of these curves.
This means that at a critical point of

is the gradient of
is the gradient of
is some scalar multiple
We call
Solving for this multiplier is relatively straightforward. Plugging this multiplier back into the equality will give us a critical point of the function.
Lagrange multipliers allow us to incorporate constraints into our optimization problem.
We can augment the original function,

At first glance it may not be obvious the relationship the Lagrangian has to the equality
If we were to optimize 

So first let’s differentiate the Lagrangian with respect to

And now

Setting these equations equal to 0 to find the critical point we get:


This is just: 

Setting that equal to 0:

We just get our equality constraint back! This is to be expected. At the critical point the constraint must be satisfied.
Being able to rewrite a constrained optimization problem in the form of the Lagrangian is actually a huge win for us. We are essentially turning a constrained optimization (the original problem) into an unconstrained optimization problem (the Lagrangian) by incorporating the constraints directly into the problem. This allows us to optimize the Lagrangian with unconstrained methods we are familiar with (gradient descent for example) and get an optimal solution to the constrained problem.
If there were multiple constraints we would add a term for each constraint and its associated Lagrange multiplier. It is often written as a sum like this:

Where 

This is still not quite enough firepower to solve the SVM primal problem. The constraints in the SVM problem are inequality constraints, and those are a bit more complicated.
Karush-Kuhn-Tucker Conditions
The Karush-Kuhn-Tucker approach expands upon the Lagrangian to incorporate inequality constraints into the function as well. It is sometimes referred to as the “Generalized Lagrangian” for that reason.
The Generalized Lagrangian looks like this:

Note: whether you subtract or add the product of the constraints and the Lagrange multipliers to the original function is up to you. It does not change the optimal points. I’ve seen it more frequently written as an addition so I will use that form going forward.
The Lagrangian we looked at earlier is still there. We have also added on terms for the inequality constraints and their associated multipliers. In this formulation the 
The basic idea behind the KKT approach is that, at the optimal solution, some of the inequality constraints will hold with strict equality. This means that they will act like equality constraints. These constraints are called active constraints. The inequality constraints that do not hold with strict equality are called inactive constraints.
If the inequality constraint is inactive, they may exclude potential optimal solutions, but an optimal solution with the constraint is still optimal if the constraint is removed. Their Lagrange multipliers should be set to 0.
The KKT approach lays out four conditions for optimality called the KKT conditions:
- Stationarity Condition:
. At an optimal point the gradient of the Lagrangian is 0.
- Primal Feasibility: The solution must satisfy the original constraints.
- Dual Feasibility The inequality constraints on the problem fall into two categories: active and inactive. Active inequality constraints are inequality constraints that are satisfied with strict equality at the optimal solution. Lagrange multipliers associated with active constraints must be non-negative. Inactive constraints should have a Lagrange multiplier of
.
- Complementary Slackness: Each inequality constraint must either have a Lagrange multiplier of

SVM Dual
We can reformulate the optimization problem posed by the SVM Primal into a new form called the SVM dual.
Starting with the SVM Primal:

subject to

We can get rid of the original inequality constraints by writing this in the Lagrangian form:

One important thing to note before we go any further is that there is one Lagrange multiplier 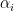
The dual formulation of the primal is the minimum of this function which maximizes the minimization problem posed by the Lagrangian.
![max_{\alpha}[min_{w, b}\mathcal{L}(w, b, \alpha)]](https://s0.wp.com/latex.php?latex=max_%7B%5Calpha%7D%5Bmin_%7Bw%2C+b%7D%5Cmathcal%7BL%7D%28w%2C+b%2C+%5Calpha%29%5D+&bg=ffffff&fg=000&s=2&c=20201002)
In other words, the dual function is the smallest possible output of the Lagrangian over all possible values of 


Of course, the Lagrangian will be at a minimum when its derivative is 0. In other words, the gradient vector of the Lagrangian must be the zero vector.
So let’s differentiate the Lagrangian with respect to


We can use these equations to solve for the optimal point of our Lagrangian. First, I will expand the summation in the Lagrangian:

Now, we can plug the equations for where the partial derivatives of

It is a fact about vectors that 


Again, plugging in our equation for



Therefore, our final dual formulation becomes:

Subject to two constraints. The first constraint comes from the Dual Feasibility KKT condition, and it says that all of the Lagrange multipliers must be non-negative:

The second constraint comes from the equation we got when finding the partial derivative of

This is called the SVM Dual. It may not be immediately obvious in what way this form is superior to the primal. It looks more complicated!
For one, we’ve now rewritten our optimization problem in terms of only one decision variable. The SVM Primal is in terms of the weight vector
Truthfully, the biggest reasons to use the dual form as opposed to the primal I have not covered yet, namely kernels and SMO. We will get there when we get there, but for now you should familiarize yourself with the SVM dual, because it is the function we will be dealing with for the rest of this series.
Conclusion
This was a pretty theory-heavy post. It was mostly a crash-course in optimization, covering the techniques we will need to train an SVM. In the next blog post we will get hands on, and use the SVM Dual formulation to train an SVM from scratch.
Thank you for reading!

Leave a comment