Introduction
This is the fourth installment in a series of blog posts about Support Vector Machines. If you have not read the first three blog posts, I highly recommend you go back and read those before continuing to this blog post.
Last time we talked about Quadratic Programming, and successfully used a QP solver to train a Support Vector Machine to classify linearly separable data. What if our data is not linearly separable? Are we out of luck?
The answer is no. We can modify our SVM formulation to accommodate data that is not perfectly linearly separable. This new formulation is called Soft Margin SVM.
Linearly Separable Data
First of all, what do we mean when we say linearly separable data?
In the first blog post, I described some data that looked like this:

This data is perfectly linearly separable. There is a straight line that separates the classes perfectly. There are no green “x”s on the positive side, nor are there yellow triangles on the negative side.
In reality, things get messy. You will more frequently encounter data sets that are not perfectly linearly separable. It might look something like this:

It’s still mostly linearly separable, but some data points are outliers.
How do we modify our formulation of SVM to allow for some of these outliers, and still draw the ideal decision boundary?
First, we will need some way of quantifying how “off” the outlier data points are.
Hinge Loss
Hinge loss is a loss function used in maximum margin classifiers (like SVM). It gives us a measure of how far off our training data point is from being classified correctly. The formula looks like this:

is the label
is the “score”. Any observation with a score above or on the positive support vector is going to have a score
1. Vice versa for the negative support vector.
I think the best way to gain an intuition about how hinge loss works is to look at some data points and calculate their hinge loss.
For example, consider this data point:

It is of the positive class 


Let’s say it has a score of 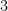


It has a loss of 0, which is what we’d expect. It is comfortably on the right side of the decision boundary.
If you notice, any point from the positive class that is on or to the right of the positive support vector will have a hinge loss of 
What about this point?

It’s not on the correct side of the support vector. It is the negative class (

As you can see there is some loss assigned to it, but it will be a small value.
Here is a graph of what the hinge loss function looks like:

It is called the hinge loss because it looks like a hinge. Anytime that the “score” multiplied by the label is greater than 1, the hinge loss becomes 0. This is true of all data points that are on the correct side of their respective support vectors.
For data points whose 
For data points whose
Modifying Hard Margin SVM
All we need to do to modify our SVM formulation to accommodate data that is not perfectly linearly separable is to add a hinge loss penalty term to the SVM Primal function:

Becomes:

We’re trying to minimize the average hinge loss across all of our training examples, but we are also trying to minimize the magnitude of the weight vector: 


You will often see it written this way:

Where 

We also need to incorporate

If the hinge loss is 0, we get the original constraint back.
We also add a constraint to enforce that the slack variable be non-negative (as the hinge loss must be non-negative):

So, all together the Soft Margin SVM Primal becomes:
subject to:


Soft Margin SVM Dual
What about the dual?
Let’s derive the dual form again starting with this new primal form.
First, we form the Lagrangian:

This is pretty similar to the Lagrangian we saw in the hard-margin case, except the original objective function now has the slack variables in it, and we add an extra term at the end for the new inequality constraint. These new constraints get its own set of Lagrange multipliers, 
Now, we differentiate the same way we did before. The partial derivatives with respect to 



We have another variable to differentiate with respect to: 

Let’s rearrange the summations in the Lagrangian the same way we did in our original derivation, only this time we need to include the terms we added:


Now we can plug in our equations for the partial derivatives of
Let’s start with


Now


Finally,


We plug our equation in for

After rearranging terms what we’re left with for our final dual formulation objective function is:

It’s the same! This is an amazing result.
The constraint associated with the Stationarity Condition stays the same. The equation we get when differentiating the Lagrangian with respect to

However, we now have two inequality constraints:


We need to rewrite our inequality constraint on 
Solving this equation for 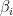


Substituting this equation for


Combining these two constraints gives us:

So, after all that the only thing that changes in the dual formulation is that we now have this extra inequality constraint on
Solving Soft Margin SVM with CVXOPT
How do we need to change the code we wrote in the last blog post to handle this new formulation?
Well, the only thing that changed was our inequality constraints. If you remember, in the last post we started with the constraint:
But we needed to rewrite it into a form the QP solver was happy with. All inequality constraints must be in less than or equal to form when fed into the QP solver.
Let’s take our new constraint and transform it into a QP-friendly form:
First, we break this up into two separate constraints:

Now, as before we need these to both be in less than or equal to form. The first inequality already is. We do the same thing we did last time and multiply both sides by -1 to flip the alligator mouth of equation two:

The only lines of code we need to modify are the matrix 

Here was what we had:
G = matrix(-np.eye(n))
h = matrix(np.zeros(n))
This handles the 
G = matrix(np.vstack((-np.eye(n), np.eye(n))))
h = matrix(np.hstack((np.zeros(n), np.full(n, C))))
Those are the only lines we need to change! Of course,
Here is the full, modified code again, so that you don’t need to go back to the previous blog post:
### Solving the SVM Dual with QP
from cvxopt import matrix, solvers
import numpy as np
import matplotlib.pyplot as plt
# Data Set
X = np.array([
[1, 4],
[4, 4],
[2, 6],
[8, -1],
[6, -2],
[9, -3]
]) * 1.0
y = np.array([-1, 1, -1, 1, -1, 1]) * 1.0
# Create masks for positive and negative labels
mask_positive = y == 1
mask_negative = y == -1
plt.scatter(X[mask_positive, 0], X[mask_positive, 1], color='red')
plt.scatter(X[mask_negative, 0], X[mask_negative, 1], color='blue')
#### Solve with QP
C = 3.0
n, m = X.shape
X_hat = X * y.reshape(-1, 1)
P = matrix(np.dot(X_hat, X_hat.T))
q = matrix(-np.ones((n, 1)))
G = matrix(np.vstack((-np.eye(n), np.eye(n))))
h = matrix(np.hstack((np.zeros(n), np.full(n, C))))
A = matrix(y.reshape(1, -1))
b = matrix(0.0)
sol = solvers.qp(P, q, G, h, A, b)
alphas = np.array(sol['x'])
# Get the indices of the support vectors
S = (alphas > 1e-8).flatten()
# Compute weights
w = np.zeros(2)
for i, x in enumerate(X):
w += alphas[i] * y[i] * x
# Compute bias
b = 0
for x, y in zip(X[S], y[S]):
b += (y - np.dot(w, x))
b /= len(S[S == True])
# Draw the decision boundary
x1 = np.linspace(0, 10, 50) # Generate 100 points for x1
x2 = (-w[0] * x1 - b) / w[1] # Calculate x2 using the equation of the decision boundary
plt.scatter(X[mask_positive, 0], X[mask_positive, 1], color='red')
plt.scatter(X[mask_negative, 0], X[mask_negative, 1], color='blue')
plt.xlabel('Height')
plt.ylabel('Weight')
plt.plot(x1, x2, color='purple')
Conclusion
SVM is becoming more powerful for us. Now we can separate noisy data that isn’t perfectly linearly separable. In the next blog post, we will look at kernels and the kernel trick, which will make SVMs even more powerful, and allow us to classify data that is not linearly separable at all.
Thank you for reading!

Leave a comment