Introduction
This is the seventh installment in a series of blog posts about Support Vector Machines. If you have not read the first six blog posts, I highly recommend you go back and read those before continuing to this blog post.
Before, we implemented SVM using a Quadratic Programming solver in Python called CVXOPT. This worked for our purposes, but as we discussed QP solvers are fraught with peril and there was something fundamentally unsatisfying about relying on one of these solvers. This is supposed to be from scratch, after all!
Last time we talked about Sequential Minimal Optimization (SMO), an algorithm for training SVMs that looks to solve the smallest possible optimization problem at every step. In SMO we solve for two Lagrange multipliers at a time. In the previous blog post, we derived an equation for the analytical solution to one of the Lagrange multipliers.
In this blog post, we will be implementing SMO from scratch in Python using no special machine learning libraries.
The SVM Class
As we discussed last time, in its simplest form, SMO goes like this:
- Select two Lagrange multipliers,
and
to optimize.
- Solve for
- Clip this solution for
and
.
- Repeat until convergence.
We will be building up an SVM class piece by piece, using SMO under the hood to train our classifier.
We can start with the boilerplate:
class SVM:
def __init__(self, X, y, C=1.0):
self.X = X
self.y = y
self.C = C
self.tol = tol
self.w = w = np.zeros(X.shape[1])
self.b = 0
self.alphas = np.zeros(X.shape[0])
This should be pretty self-explanatory although there is one important thing to note: the Lagrange multipliers (alphas) must be initialized to a feasible value. This is to satisfy the KKT conditions: 
Next, we will need our SVM to be able to make a guess. This is needed when we want to use the SVM to make predictions, but also in the implementation of the SMO algorithm for calculating the 
Recall from our derivation of the dual that the optimal 

The output of our SVM is 

Where 


So, we calculate our guess like this:
def guess(self, x):
return (self.alphas * self.y) @ self.kernel(X, x.T) + self.b
In our final implementation, we would like to offer many different kinds of kernel functions, but for the sake of simplicity right now we will only implement a linear kernel function 
def kernel(self, x_i, x_j):
return np.dot(x_i, x_j)
Now comes the good part: implementing SMO. At a high level, the usage code for our SVM object will look like this:
svm = SVM(X, y)
svm.fit()
The fit() function is where all of the training happens.
As I said in the previous part, there is an entire component of the SMO algorithm that is heuristics for choosing which pair of Lagrange multipliers to optimize next. We will get to that, but for right now it works to just choose two random Lagrange multipliers and optimize them. This is the simplest possible thing we can do to get our implementation off the ground.
def fit(self, iter=300):
for _ in range(iter):
a_1 = random.randrange(0, self.X.shape[0])
a_2 = random.randrange(0, self.X.shape[0])
self.take_step(a_1, a_2)
The take_step function is where the heavy lifting happens. It is a simplified version of the pseudo-code from the paper for the most part. Let’s walk through it line by line:
def take_step(self, i1, i2):
if(i1 == i2):
return
If we happen to have chosen the same two Lagrange multipliers we just want to return. We need to optimize two Lagrange multipliers at once for the algorithm to work.
alph1 = self.alphas[i1] # Lagrange multiplier for example 1
alph2 = self.alphas[i2] # Lagrange multiplier for example 2
y1 = self.y[i1] # label for example 1
y2 = self.y[i2] # label for example 2
E1 = self.guess(self.X[i1]) - y1 # error in example 1
E2 = self.guess(self.X[i2]) - y2 # error in example 2
s = y1 * y2
We pull out the two Lagrange multipliers we will be working with. Each Lagrange multiplier is associated with a training example. We pull out the label associated with that training example and calculate the error (the difference between the prediction and the true label value). We also initialize that 
L = 0
H = 0
if y1 == y2:
L = max(0, alph1 + alph2 - self.C)
H = min(self.C, alph2 + alph1)
else:
L = max(0, alph2 - alph1)
H = min(self.C, self.C + alph2 - alph1)
if L == H:
return
These are the
k11 = self.kernel(self.X[i1], self.X[i1])
k12 = self.kernel(self.X[i1], self.X[i2])
k22 = self.kernel(self.X[i2], self.X[i2])
eta = k11 + k22 - 2 * k12
Here we calculate the kernel values 



if(eta > 0):
new_a2 = alph2 + y2 * (E1 - E2) / eta
new_a2 = max(new_a2, L)
new_a2 = min(new_a2, H)
else:
return
This is probably the most important part of the code. This is the solution to 
In special cases,
We add an extra check at this point to see if our update to
if abs(new_a2 - alph2) < 10e-3 * (new_a2 + alph2 + 10e-3):
return
Now, with our new value of
Recall the equality from the last blog post:

This means that:


new_a1 = alph1 + s * (alph2 - new_a2)
Now we need to update 
We could just find our weight vector at the end given our final 

We can update our

The summation not involving our updated Lagrange multipliers 

In terms of code, we update the weight vector like this:
self.w = self.w + (new_a1 - alph1) * y1 * self.X[i1] + y2 * (new_a2 - alph2) * self.X[i2]
We can do something similar for guess(),
There are three possible scenarios:
- Both are not at the bounds.


In the first scenario we can pick a valid 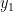

The second scenario is similar only we force the output to be 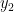

If neither Lagrange multipliers are at bounds both 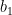
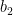

b1 = self.b - E1 - y1 * (new_a1 - alph1) * k11 - y2 * (new_a2 - alph2) * k12
b2 = self.b - E2 - y1 * (new_a1 - alph1) * k12 - y2 * (new_a2 - alph2) * k22
if 0 < new_a1 < C:
b_new = b1
elif 0 < new_a2 < C:
b_new = b2
else:
b_new = (b1 + b2) * 0.5
self.b = b_new
And finally, we update the value of our Lagrange multipliers:
self.alphas[i1] = new_a1
self.alphas[i2] = new_a2
Here is the SVM class in its entirety:
import numpy as np
import random
class SVM:
def __init__(self, X, y, C, tol=10e-3):
self.X = X
self.y = y
self.C = C
self.tol = tol
self.w = w = np.zeros(X.shape[1])
self.b = 0
self.alphas = np.zeros(X.shape[0])
def guess(self, x):
return (self.alphas * self.y) @ self.kernel(X, x.T) + self.b
def kernel(self, x_i, x_j):
return np.dot(x_i, x_j)
def get_b(self):
return np.mean(self.y - np.dot(self.w.T, self.X.T))
def take_step(self, i1, i2):
if(i1 == i2):
return
alph1 = self.alphas[i1] # Lagrange multiplier for example 1
alph2 = self.alphas[i2] # Lagrange multiplier for example 2
y1 = self.y[i1] # label for example 1
y2 = self.y[i2] # label for example 2
E1 = self.guess(self.X[i1]) - y1 # error in example 1
E2 = self.guess(self.X[i2]) - y2 # error in example 2
s = y1 * y2
L = 0
H = 0
if y1 == y2:
L = max(0, alph1 + alph2 - self.C)
H = min(self.C, alph2 + alph1)
else:
L = max(0, alph2 - alph1)
H = min(self.C, self.C + alph2 - alph1)
if L == H:
return
k11 = self.kernel(self.X[i1], self.X[i1])
k12 = self.kernel(self.X[i1], self.X[i2])
k22 = self.kernel(self.X[i2], self.X[i2])
eta = k11 + k22 - 2 * k12
if(eta > 0):
new_a2 = alph2 + y2 * (E1 - E2) / eta
if new_a2 <= L:
new_a2 = L
elif new_a2 >= H:
new_a2 = H
else:
return
if abs(new_a2 - alph2) < 10e-3 * (new_a2 + alph2 + 10e-3):
return
new_a1 = alph1 + s * (alph2 - new_a2)
b1 = self.b - E1 - y1 * (new_a1 - alph1) * k11 - y2 * (new_a2 - alph2) * k12
b2 = self.b - E2 - y1 * (new_a1 - alph1) * k12 - y2 * (new_a2 - alph2) * k22
if 0 < new_a1 < C:
b_new = b1
elif 0 < new_a2 < C:
b_new = b2
else:
b_new = (b1 + b2) * 0.5
self.b = b_new
self.w = self.w + (new_a1 - alph1) * y1 * self.X[i1] + y2 * (new_a2 - alph2) * self.X[i2]
self.alphas[i1] = new_a1
self.alphas[i2] = new_a2
return
def fit(self, iter=300):
for _ in range(iter):
a_1 = random.randrange(0, self.X.shape[0])
a_2 = random.randrange(0, self.X.shape[0])
self.take_step(a_1, a_2)
That’s enough to start using the SVM:
import matplotlib.pyplot as plt
# Data Set
X = np.array([
[1, 4],
[4, 4],
[2, 6],
[8, -1],
[6, -2],
[9, -3]
]) * 1.0
y = np.array([1, 1, 1, -1, -1, -1])
svm = SVM(X, y)
svm.fit()
#Create masks for positive and negative labels
mask_positive = y == 1
mask_negative = y == -1
plt.scatter(X[mask_positive, 0], X[mask_positive, 1], color='red')
plt.scatter(X[mask_negative, 0], X[mask_negative, 1], color='blue')
# Draw the decision boundary
x1 = np.linspace(0, 10, 50) # Generate 100 points for x1
x2 = (-svm.w[0] * x1 - svm.b) / svm.w[1] # Calculate x2 using the equation of the decision boundary
plt.plot(x1, x2, color='purple')
This gives us:

As you can see it successfully found (approximately) the ideal decision boundary.
It can handle data that is not perfectly linearly separable as well:

Iris Dataset
So far we have only looked at toy examples. We don’t need pages and pages worth of derivations for an algorithm to separate six red and blue dots.
As a more practical example of what we’re able to do with Support Vector Machines, let’s apply our newly implemented SVM class to the Iris dataset.
First, we load the iris dataset:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
SVMs are binary classifiers. We can only separate two classes. In future blog posts, we will discuss ways that you can use SVMs for multi-class classification problems. For now, we will just be drawing the decision boundary which separates Iris-setosa from everything else.
y = np.where(y == 0, 1, -1)
For the sake of this blog post and the ability to graph the decision boundary, I will project this data down to two dimensions using Principal Component Analysis. For more information, read my blog post about Singular Value Decomposition.
pca = PCA(n_components=2)
skPCA = pca.fit_transform(iris.data)
Now we train our SVM:
svm = SVM(skPCA, y, 1)
svm.fit()
And look at that:

This is cool, but it is still a somewhat trivial example. In the next blog post, we will look at how we can use our SVM to read handwriting.
Conclusion
This is a good start to implementing SMO. There are still many optimizations and features to add, but I wanted to get the simplest form of the algorithm working and build it up in future blog posts.
In the next blog post, we will improve our SVM class by implementing a real outer loop that chooses Lagrange multipliers to optimize in a more principled way and expand it to work with non-linear kernels.
Thank you for reading!

Leave a comment