Introduction
In the previous blog post, we began the implementation of our feedforward neural net, and went over the equations and code for the forward pass.
With this, we can now feed our data through the network, but its not of much use without being able to train it. In order to train our recurrent neural network, we need to implement the backpropagation through time algorithm.
If you have not read my blog post on the basics of backpropagation, I highly recommend you read that (and the rest of the feedforward neural net series) before reading this blog post.
Loss Function
Before we can begin training our neural net we need a way of measuring how well our network is actually performing, i.e. a loss function.
We will be using a negative log loss function. This choice is motivated mainly by the fact that our problem is a classification problem (“which character comes next?”), and our output layer, being softmax, represents a probability distribution.
Any choice of loss function would work in principle, but the equations I will be deriving are specifically for the network discussed in the last blog post, and a negative log loss function.
Negative log loss looks like this:

is the full output vector from the softmax output layer for time step
. Each element represents a probability (between 0 and 1) that the output is of the class associated with that element in the vector.
is the element of the full output vector associated with the true label value.
Note that this is the loss for a single timestep. The total loss for the whole sequence can be computed in different ways. Simply summing the losses for each time step, or taking an average are both valid. We’ll be summing them.
loss = 0
for t, (y_hat, target_seq) in enumerate(zip(os, target)):
target_index = target_seq.argmax().item()
loss += -np.log(y_hat[target_seq.argmax().item()])
Our computation graph now includes the nodes for the loss at each timestep, with the output of the neural net and the true label value as inputs:
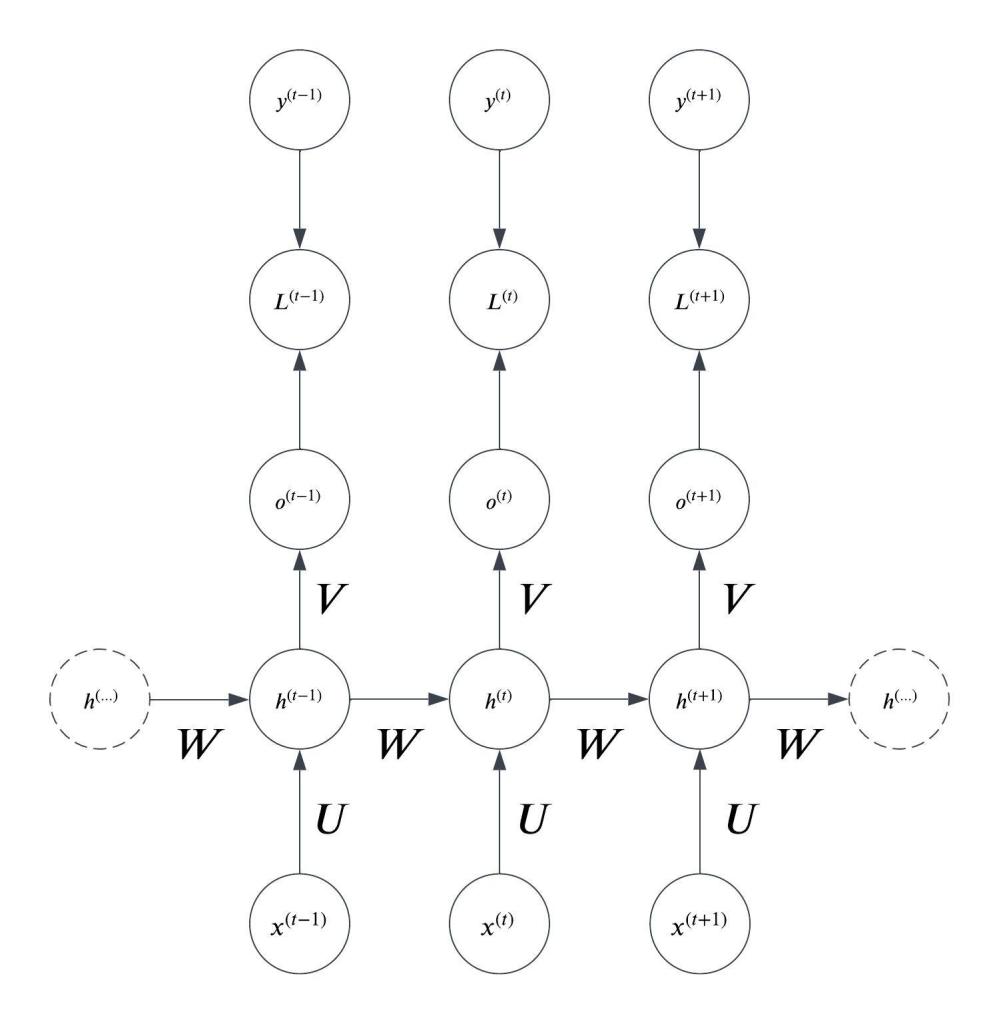
Our goal is to drive this loss function as low as possible during training. To do that, we need to compute the gradient of the loss with respect to the parameters.
Backpropagation Through Time
The basic idea of the backpropagation through time algorithm is that, once we have the unfolded computation graph laid out before us, we can backpropagate through it as though it were one long connected feedforward neural net.
While each node in the computation graph above actually represents an entire layer of neurons, I will be making the simplifying assumption during much of this derivation that each layer is in fact only one neuron large.
I find this helpful for understanding how the equations are derived, and it’s not difficult to generalize to the matrix/vector case afterwards.
Starting from the loss node for the final time step in the computation graph we work recursively backwards, computing the gradient of each node with respect to the loss using the chain rule.
Autograd engines like the one in PyTorch actually construct this computation graph automatically behind the scenes when you do operations with tensors. When you call .backward(), it backpropagates through that computation graph automatically. This is especially helpful in recurrent neural nets because it means that you don’t need to keep the hidden states around for training. This being from scratch, we will be implementing the backpropagation by hand.
The first node (the loss itself) is obvious:

Output Layer
The next step is to find the partial derivative of the loss with respect to the output at each timestep.
To do this we use the chain rule:

Since 

Now, to find the derivative of the loss for time step

First we differentiate the loss function with respect to 
The loss function is:

Now we find the partial derivative of
Recall that the output is softmax:

To find: 


We can separate this fraction out:

Simplifying and plugging in our equation for

And finally we return to this equation:


Where the 
With this, we can begin implementing the backpropagation for our RNN class:
def backward(self, input, target, outputs, hs):
time_steps = len(input)
# Output layer
dLdots = [np.zeros(self.output_size) for _ in range(time_steps)]
for t in range(time_steps):
dLdot = outputs[t] - target[t]
dLdots[t] = dLdot
Hidden Layers
For the hidden layer associated with the final timestep, 
Note that in this case 
Therefore, the gradient for this layer is:

We computed 

Recall that when we feed the activations of 

Therefore:

In our simple one-neuron-per-layer example, this would just be a scalar number and transposing it makes no sense. In a real scenario though
Putting it all together we get:

Backwards Through Time
Given the gradient of the hidden layer for the final time step
In the previous section, we found the gradient of the hidden layer of the final timestep. We want to find 
There are two descendants of 


We already know 


This is of course just more chain rule.
We already know 

I’d like to first focus on:

Recall that the equation for

And the equation for 

Once again, our simplifying assumption is that all of the layers are one neuron. So I will write 
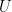

From these equations we can see that:

Now we can differentiate this with respect to

If you’re confused as to how I came up with this please review my blog post about the derivative of the hyperbolic tangent activation function.
Now, time for 
In the general case, where our layers can have an arbitrary number of neurons, our equation for

But once again we made the simplifying assumption that

This means that:

Now, putting this all together we can come up with the final equation for the derivative of the loss with respect to the hidden layer

How does this change when the layers are allowed to be arbitrarily large?



I’ve left 



If 

If not, you will use the last output if this calculation for
In terms of code, backpropagating through the hidden layers looks like this:
# Hidden Layers
dLdhts = [np.zeros(self.hidden_size) for _ in range(time_steps)]
dLdhtau = self.V.T @ dLdots[time_steps - 1]
dLdhts[time_steps - 1] = dLdhtau
for t in range(time_steps - 2, -1, -1):
prev_dht = dLdhts[t + 1]
dLdht = self.W.T @ (prev_dht @ np.diag(1 - hs[t + 1]**2)) + (self.V.T @ dLdots[t])
dLdhts[t] = dLdht
This is different from the code for backpropagating through the outputs in two important ways:
- The order matters. We need to start from the final timestep and go backwards.
- Because the final timestep is a special case, I’m computing the final timestep outside the loop that works its way back through the timesteps.
Backpropagating to Parameters
We have backpropagated through all of the nodes in the computation graph. We can now begin finding the gradients with respect to the parameters.
V
First let’s start with the weight matrix connecting the hidden layer to the output layer:
You know the drill. We will make our simplifying assumption of one-neuron layers then generalize to the arbitrarily sized layer case.
We can find the partial derivative of the loss with respect to 

We already know
Differentiating

So this means:

To generalize this to arbitrarily sized layers

### Parameters
# V
dLdV = np.zeros_like(self.V)
for t in range(time_steps):
dLdV += dLdots[t].reshape(-1, 1) @ hs[t].reshape(-1, 1).T
W


Making our single-neuron simplifying assumption:

Now we can compute the partial derivative of the loss with respect to 

This is the contribution of the weight to the total loss for one time step. This creates some ambiguity in the notation as written. How exactly do we compute: 
To resolve this ambiguity, we simply make a copy of the weight 

We already know 
Differentiating the equation for

So we plug that back into our equation for the partial derivative of the weight:

Generalizing this to the vector case:

Where:
is the Jacobian of the hyperbolic tangent for
is a vector where each entry is the value of the preceding hidden layer’s activation
# W
dLdW = np.zeros_like(self.W)
for t in range(time_steps - 1, 0, -1):
dLdW += np.diag(1 - hs[t]**2) @ dLdhts[t].reshape(-1, 1) @ hs[t - 1].reshape(-1, 1).T
U

Once again we make our simplifying assumption of a single neuron:

Again we apply the chain rule:

Differentiating 

Putting this together and into vector form we get:

# U
dLdU = np.zeros_like(self.U)
for t in range(time_steps):
word = input[t]
dLdU += np.diag(1 - hs[t]**2) @ dLdhts[t].reshape(-1, 1) @ word.reshape(1, -1)
c
The only place where 
Therefore the partial derivative of

We differentiate

Therefore the derivative with respect to the loss is just:

However, this is only for timestep

b
Now the bias for the hidden layer, 
Once again we apply the chain rule. We have already computed the gradient for
Differentiating this with respect to

We once again make our simplifying assumption of one neuron per layer just to derive these equations in scalar form:

In vector form, this would be:

Therefore:

This gives us the gradient for one time step. We need to sum over all of the time steps to get the final gradient:

# b
dLdb = np.zeros_like(self.b)
for t in range(time_steps):
a = np.diag(1 - hs[t]**2)
b_ = dLdhts[t].reshape(-1, 1)
dLdb += (np.diag(1 - hs[t]**2) @ dLdhts[t])
Conclusion
This concludes our breakdown of the backpropagation through time algorithm. It may seem complicated, but once you understand that we are doing regular backpropagation through what is essentially one long feedforward network (the unfolded computation graph) it’s not so bad.
Now that we have the gradients of the parameters with respect to the loss function, we can train our neural net. Next time, we’ll finish up, implementing the method for training our RNN and use it to generate some fake names.
Here is the backward() method in its entirety:
def backward(self, input, target, outputs, hs):
time_steps = len(input)
# Output layer
dLdots = [np.zeros(self.output_size) for _ in range(time_steps)]
for t in range(time_steps):
dLdot = outputs[t] - target[t]
dLdots[t] = dLdot
# Hidden Layers
dLdhts = [np.zeros(self.hidden_size) for _ in range(time_steps)]
dLdhtau = self.V.T @ dLdots[time_steps - 1]
dLdhts[time_steps - 1] = dLdhtau
for t in range(time_steps - 2, -1, -1):
prev_dht = dLdhts[t + 1]
dLdht = self.W.T @ (prev_dht @ np.diag(1 - hs[t + 1]**2)) + (self.V.T @ dLdots[t])
dLdhts[t] = dLdht
### Parameters
# V
dLdV = np.zeros_like(self.V)
for t in range(time_steps):
dLdV += dLdots[t].reshape(-1, 1) @ hs[t].reshape(-1, 1).T
# W
dLdW = np.zeros_like(self.W)
for t in range(time_steps - 1, 0, -1):
dLdW += np.diag(1 - hs[t]**2) @ dLdhts[t].reshape(-1, 1) @ hs[t - 1].reshape(-1, 1).T
# U
dLdU = np.zeros_like(self.U)
for t in range(time_steps):
word = input[t]
dLdU += np.diag(1 - hs[t]**2) @ dLdhts[t].reshape(-1, 1) @ word.reshape(1, -1)
# c
dLdc = np.zeros_like(self.c)
for t in range(time_steps):
dLdc += dLdots[t]
# b
dLdb = np.zeros_like(self.b)
for t in range(time_steps):
a = np.diag(1 - hs[t]**2)
b_ = dLdhts[t].reshape(-1, 1)
dLdb += (np.diag(1 - hs[t]**2) @ dLdhts[t])
return dLdV, dLdW, dLdU, dLdc, dLdb
Thank you for reading!

Leave a comment