deep-learning
-
Introduction In the previous blog post we took a look at the backpropagation through time algorithm. We saw how, looking at the unfolded computation graph, backpropagation through time is essentially the same as backpropagating through one long connected feedforward neural net. Now that we have the gradient of the loss with respect to the parameters…
-
Introduction In the previous blog post, we began the implementation of our feedforward neural net, and went over the equations and code for the forward pass. With this, we can now feed our data through the network, but its not of much use without being able to train it. In order to train our recurrent…
-
Introduction In the previous blog post we talked about what it means exactly for data to have a “sequential topology”, and prepared our training data to be fed into the recurrent neural net. In this post, we’ll be looking at the design of our simple recurrent neural net, the equations for the forward pass, and…
-
Introduction In the previous blog post we looked at how a recurrent neural network differs from a feedforward neural network, and why they are better at sequence processing tasks. In this blog post, we will be preparing our training data, and start writing some code. Our training data is just a list of lowercase names.…
-
Introduction In a previous series of blog posts I covered feedforward neural networks. Feedforward neural networks are very powerful, but they are not the only neural network architecture available and they may be ill-suited to certain tasks. Recurrent neural nets are a class of neural nets that are particularly effective for modeling data with a…
-
The loss function is a crucial component to training neural nets. It allows us to get a measure of how well our neural net is doing. Let’s take a look at the mean squared error loss: Even if you are unfamiliar with the mean squared error loss, it should hopefully be plausible to you that…
-
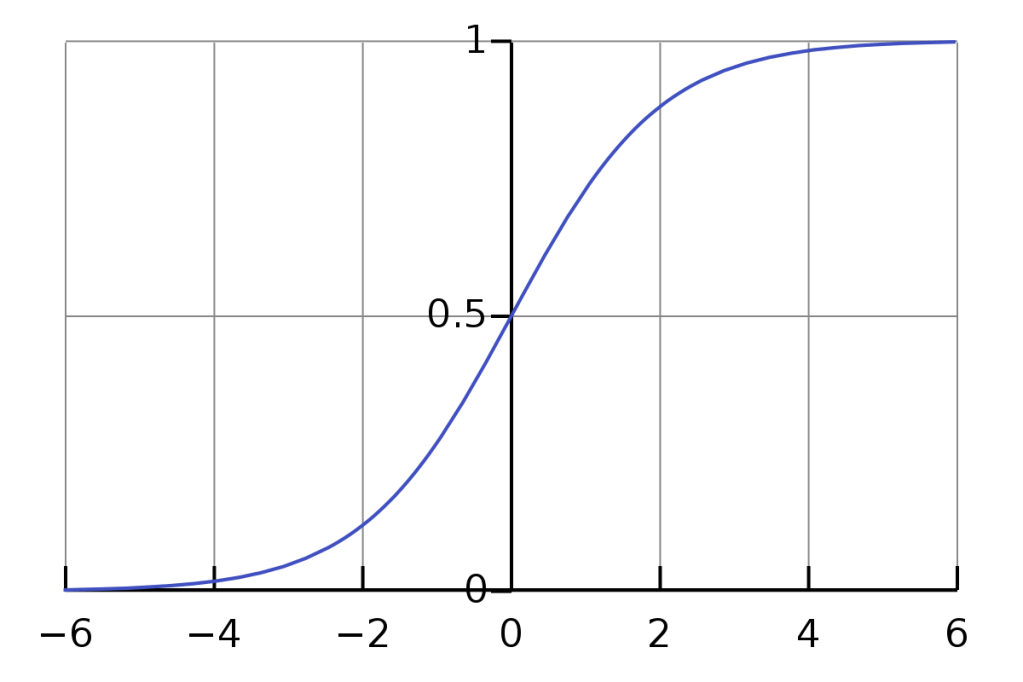
The sigmoid function, is a popular activation function for neurons in a neural net. It is necessary to use the derivative of the activation function when using backpropagation to compute the gradients of the weights and biases of the network. Here is how to find the derivative of the sigmoid function: Let’s take a look…
-

The Loss Function In order for our neural net to “learn” we first need some measure of how it is doing. This is called the loss function. It measures how far off the output of our net is from what we expect it to be. There are many kinds of loss function but they all…
-

In this post we will begin implementing our neural net. We will start by implementing the basic data structures that comprise our neural net. Then I explain what exactly happens during the forward pass, followed by the code. The Neural Net Class First thing’s first we need a neural net: Each layer in our net…
